Tracking Disagreement and Codebook Iterations during Annotation
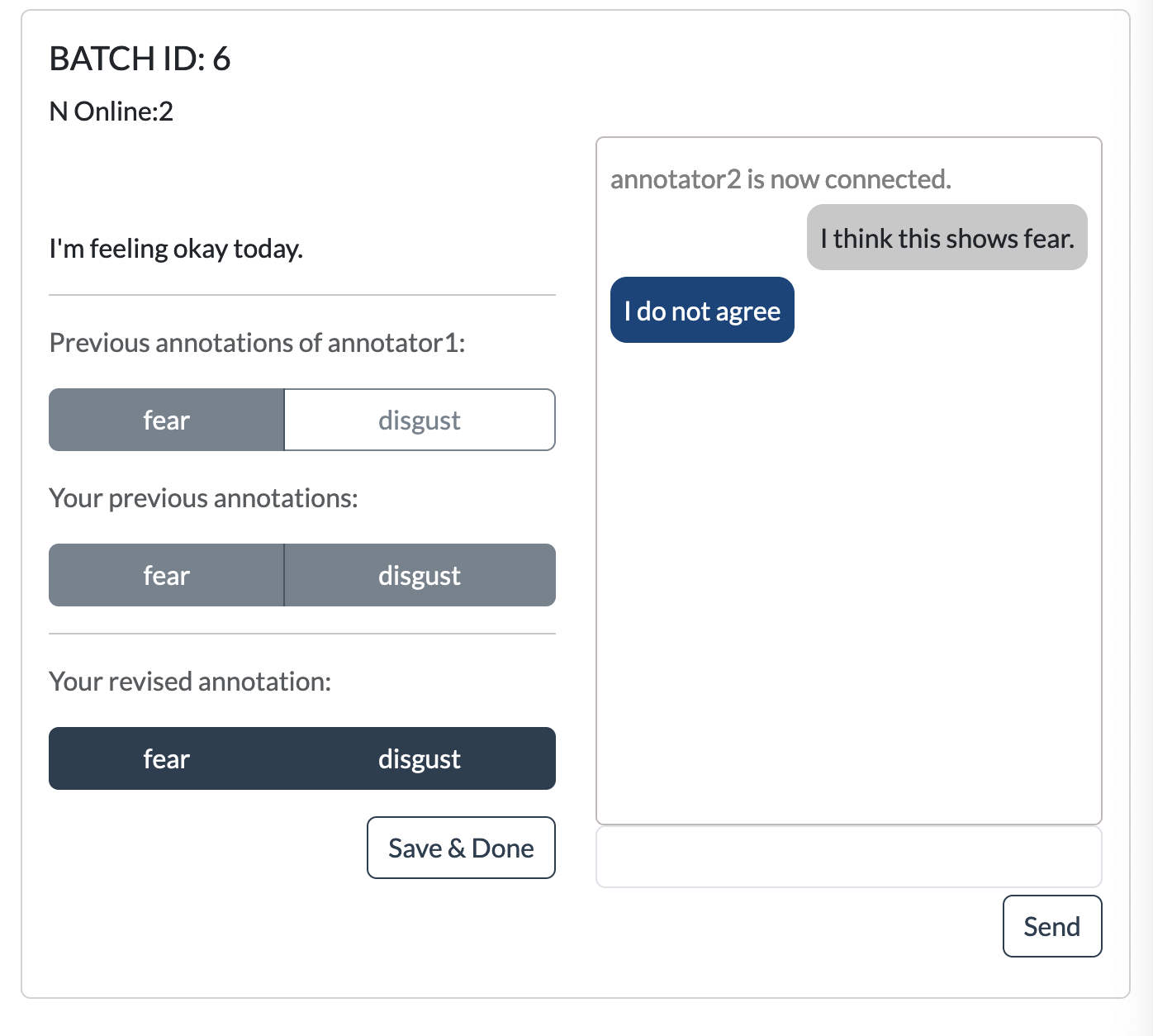
Description: In data labelling, AI/data experts define rules (a ``codebook'') of how they want labels to be, and then several data labellers apply these rules to a given dataset. Ideally, the rules are well-defined and the training data instances are unambiguous, such that there is one clear label for every training data instance. In reality, this ideal is often proven wrong, and data labelling requires negotiation and iterations of labels and rules. This process, however, is invisible in the resulting dataset and model [1,2]. To make these processes visible, we want to create a new annotation tool that tracks annotations, discussions among annotators, and links them to (iterations of) the codebook. The first prototype exists, and now we need to refine it by doing prototyping studies to find out how to improve it.
Supervisor: Susanne Hindennach
Distribution: 20% Literature, 60% implementation, 20% Analysis and discussion
Requirements: Design, Implementation, Analysis
Literature: [1] Milagros Miceli and Julian Posada. 2022. The Data-Production Dispositif. Proc. ACM Hum.-Comput. Interact. 6, CSCW2, Article 460 (November 2022), 37 pages. Paper link.
[2] Milagros Miceli, Tianling Yang, Adriana Alvarado Garcia, Julian Posada, Sonja Mei Wang, Marc Pohl, and Alex Hanna. 2022. Documenting Data Production Processes: A Participatory Approach for Data Work. Proc. ACM Hum.-Comput. Interact. 6, CSCW2, Article 510 (November 2022), 34 pages. Paper link.