Who's Who? Referent Disambiguation in Video Question Answering
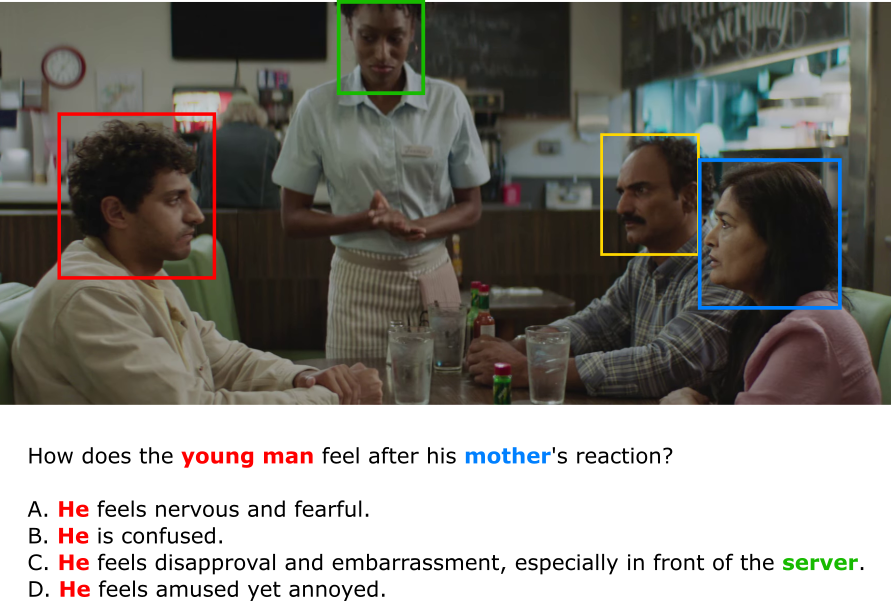
Description: In videos with multiple characters, understanding who a question refers to is essential for answering it accurately. This project tackles referent disambiguation in the MoMentS dataset [1] by linking ambiguous expressions (like "he" or "the woman in red") to the correct character on screen. You'll combine facial, visual, and linguistic cues to track and ground references across time. Emotion-LLaMA [2] will be used after disambiguation to analyze the right person's emotions.
Goals:
- Build a pipeline for character tracking and visual description extraction
- Resolve ambiguous references in text to specific individuals in video
- Use Emotion-LLaMA on the correctly grounded person for emotion reasoning
- Evaluate improvements on emotion-related VQA in MoMentS
Supervisor: Victor Oei
Distribution: 10% Literature Review, 70% Implementation, 20% Analysis
Requirements: knowledge in deep learning, computer vision, PyTorch, multimodal processing
Literature:
[1] Villa-Cueva et al. (2025). MOMENTS: A Comprehensive Multimodal Benchmark for Theory of Mind.
[2] Cheng et al. (2024). Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning.