Multimodal Models Meet Unbiased Scene Graphs
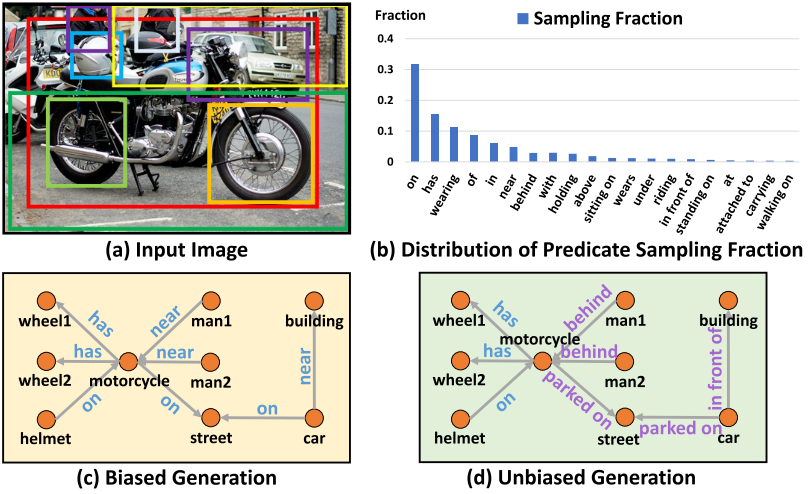
Description: Current multimodal models benefit from better feature representations brought by the advent of Graph Neural Networks [1]. These models represent images as graphs where the nodes are the object features and the edges depict the relationship between them. This approach has been successful for a variety of tasks such as Visual Dialog [2] and VQA [3]).
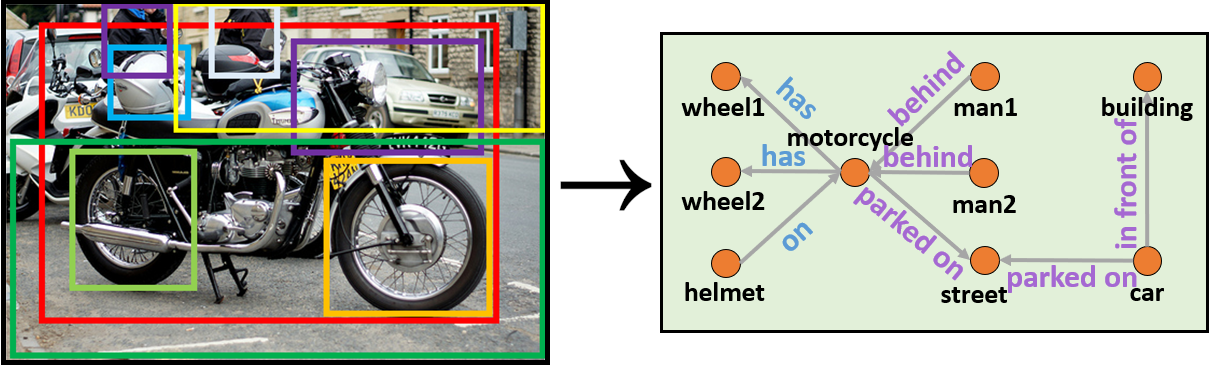
However, current approaches leverage graph scene generation models that were trained on biased data [4, 5, 6] and, thus, neglect rich scene information. Recently Tang et al. proposed an approach to alleviate this drawback, i.e. an unbiased scene graph generation scheme [7].
In this thesis, we want to research if and how this unbiased scene generation scheme would affect downstream multimodal tasks (e.g. Visual Dialog and VQA) in terms of feature expressivity and overall performance. To this end, we generate new unbiased scenes for both tasks and train existing models (i.e. CAG [8] for Visual Dialog and ReGAT [9] for VQA) with this data and compare the performance with that obtained from biased scene graphs.}
Supervisor: Adnen Abdessaied
Distribution: 15% Literature, 70% Implementation, 15% Analysis
Requirements: Strong programming skills in Python PyTorch, strong knowledge in Deep Learning in general and GNNs in particular, previous experience in CV and NLP
Literature:
[1] Wu, Zonghan, et al. 2020. A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems (TNNLS).
[2] Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, Jose M. F. Moura, Devi Parikh, Dhruv Batra. 2017. Visual Dialog. Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[3] Antol, Stanislaw, et al. 2015. VQA: Visual Question Answering. Proceedings of the IEEE International Conference on Computer Vision (ICCV).
[4] Zhang, Hanwang, et al. 2017. Visual translation embedding network for visual relation detection. Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[5] Zellers, Rowan, et al. 2018. Neural motifs: Scene graph parsing with global context. Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[6] Tang, Kaihua, et al. 2019. Learning to compose dynamic tree structures for visual contexts. Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[7] Tang, Kaihua, et al. 2020. Unbiased scene graph generation from biased training. Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[8] Guo, Dan, et al. 2020. Iterative context-aware graph inference for visual dialog. Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[9] Li, Linjie, et al. 2019. Relation-aware graph attention network for visual question answering. Proceedings of the IEEE International Conference on Computer Vision (ICCV).