Identifying Explanation-Worthy Features in Large Language Models
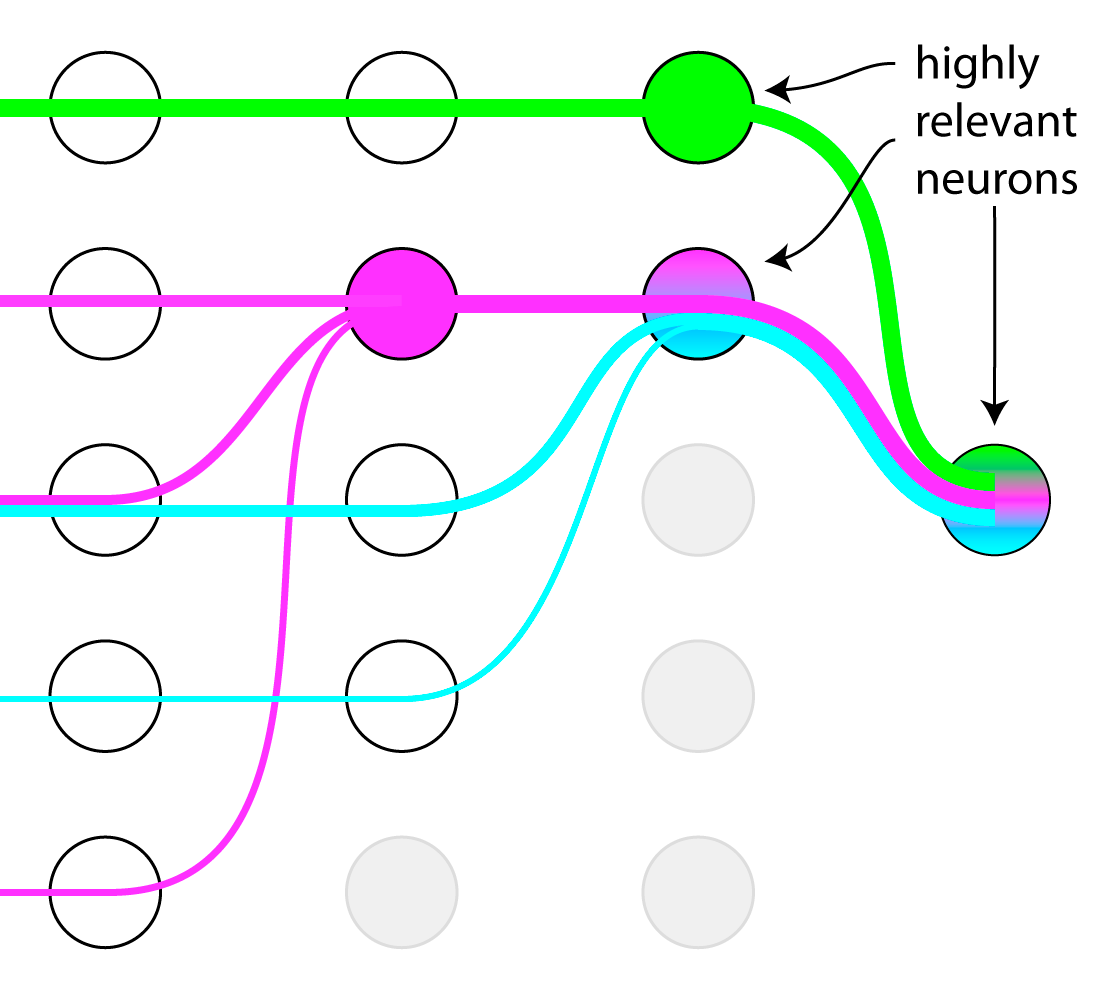
Description: Mechanistic Interpretability has brought us methods to disentangle polysemantic neurons (which represent multiple features) and superposition of features [1]. It can give us insight into what models universally learn, however for a specific prediction it is very difficult to interpret the enormous number of features to find explanation-worthy ones. One way of reducing the searchspace is to use attribution to single out features relevant to the prediction [2]. In this project you will first show empirically that we can effectively reduce the number of neurons and features to inspect and then research ways to further filter them. You will apply and extend methods from mechanistic interpretability and explainable AI to inspect the interesting features and verify them by interventions.
Goal:
- Show empirically that we can reduce the number of neurons and features per neuron using attribution methods
- Explore and implement new ways to further filter them
- Apply sparse autoencoders and concept-based explanations to interpret them
- Verify the interpretation by interventions, i.e. amplifying the activations
- Perform analysis and report on the phenomena found
Supervisor: Fabian Kögel
Distribution: 20% literature review, 30% implementation, 30% exploration, 20% analysis
Requirements: high motivation, good understanding of transformer model internals, experience in Python and PyTorch, analytical thinking.
Literature: [1] Bricken et al. "Towards monosemanticity: Decomposing language models with dictionary learning" 2023. Paper link.
[2] Templeton et al. "Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet" 2024. Paper link.
[3] Dreyer et al. “PURE: Turning Polysemantic Neurons Into Pure Features by Identifying Relevant Circuits” CVPR-W 2024. Paper link.
[4] Achtibat et al. “From attribution maps to human-understandable explanations through Concept Relevance Propagation” Nature Machine Intelligence 2023. Paper link.