Human and Machine Reasoning on Common Grounds
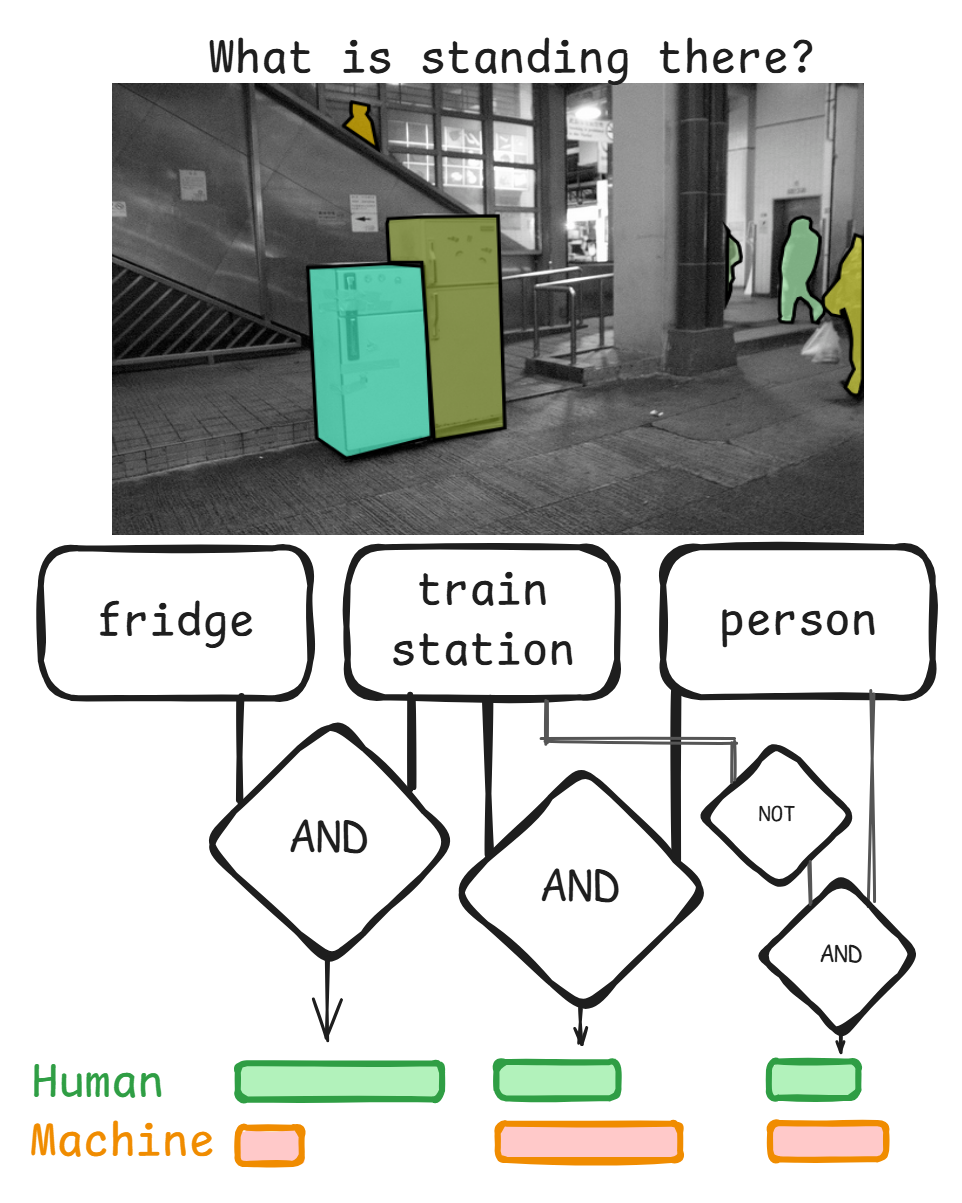
Description: When humans and machines work with each other, they need to understand each others reasoning. Prior work in visual question answering (VQA) revealed that machines tend to “look” at the same regions as humans [1] and generally learn to recognize human interpretable concepts [2]. However, shared attention does not imply shared understanding by default, meaning that humans and machines “see” the same “things” at the same regions. This project is about identifying this common ground of concepts and further how it is used in reasoning about the answer to a visual question. You will be provided with a method [1] to extract what models and humans “see” and a symbolic explainability method [2] to investigate their reasoning over these predicates. You will develop a way to trace the human reasoning from existing eye tracking data and to select VQA scenarios for comparison.
Goals:
- Identify the common ground as a set of concepts shared between human and machine
- Extract the reasoning process from models and humans
- Compare humans and models on several scenarios in VQA (e.g. object identification, localization, ambiguity)
Supervisor: Fabian Kögel
Distribution: 20% literature review, 20% experiment design, 30% implementation, 30% analysis & discussion
Requirements: high motivation, programming skills in Python and PyTorch, knowledge of deep learning and model internals, ideally explainability experience
Literature: [1] Sood et al. 2021. "VQA-MHUG: A Gaze Dataset to Study Multimodal Neural Attention in Visual Question Answering" CoNLL 2021.
[2] Achtibat et al. 2023. From attribution maps to human-understandable explanations through Concept Relevance Propagation. Nature Machine Intelligence.
[3] Schnake et al. 2025. Towards symbolic XAI — explanation through human understandable logical relationships between features. Information Fusion.
[4] Ameisen et al. 2025. Circuit Tracing: Revealing Computational Graphs in Language Models.