Deep Theory of Mind-enhanced Best Response Training
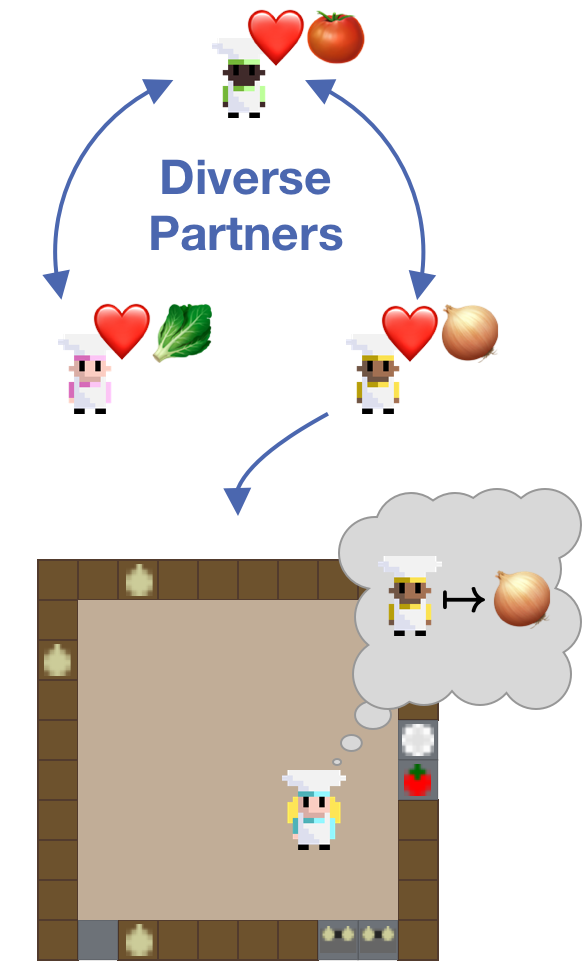
Description: Theory of Mind (ToM) [11,12] is the ability of humans to reason about the mental states (goals, desires, preferences etc.) of others around us. It is required to correctly interact with other agents, especially in cooperative settings in which agents need to align their actions to achieve a common goal [13]. We are interested in training agents capable of cooperating with humans. Our idea is to improve such agents with Theory of Mind reasoning. As training with humans is impossible and evaluating with humans expensive, researchers typically test their algorithms in Zero-shot / Ad-Hoc cooperation [1, 2, 3, 4, 5]. In Ad-hoc cooperation agents need to cooperate with an agent not previously encountered during training. This models cooperating with a human that has diverse preferences etc. and is someone the agent has never seen before. While RL agents are typically trained via self-play this is not possible in this setting as such policies tend to overadapt to themselves [1]. As a result self-play policies themselves typically fail to coordinate with novel partners, especially humans [6]. To mitigate this approaches commonly rely on training agents that are familiar with a broad set of behaviours. Typically, methods first pre-train a set of diverse agents and then rely on finding a best response to that population [2,3,4].
Your task is to:
- Reimplement one methods from Ad-hoc teamwork, HSP [4], for the Overcooked-AIv2 environment [7] in Jax
- Reuse the ToM agent architecture introduced in [8] to train a best response and compare results against ablations
- Build a model and algorithm capable of forming a model of other agents
- Use probing [9] to investigate whether and how during best response training agents learn to model intentions [10] for both your and the ablated versions
Overarching research question:
- Do Theory of Mind enhanced agents model a diverse population better and can thus engage in better zero-shot cooperation?
Supervisor: Constantin Ruhdorfer
Distribution: 20% literature review, 60% implementation, 20% analysis
Requirements: Good knowledge of deep learning and reinforcement learning, strong programming skills in Python and PyTorch and/or Jax, self management skills. The thesis requires to learn Jax along the way, experience in PyTorch will be sufficient to start.
Literature:
[1] Hengyuan Hu, Adam Lerer, Alex Peysakhovich, and Jakob Foerster. “Other-play” for zero-shot coordination. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 4399–4410. PMLR, 13–18 Jul 2020.
[2] J Strouse, Kevin McKee, Matt Botvinick, Edward Hughes, and Richard Everett. Collaborating with humans without human data. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 14502–14515. Curran Associates, Inc., 2021.
[3] Rui Zhao, Jinming Song, Yufeng Yuan, Haifeng Hu, Yang Gao, Yi Wu, Zhongqian Sun, and Wei Yang. Maximum entropy population-based training for zero-shot human-ai coordination. Proceedings of the AAAI Conference on Artificial Intelligence, 37(5):6145–6153, Jun. 2023.
[4] Chao Yu, Jiaxuan Gao, Weilin Liu, Botian Xu, Hao Tang, Jiaqi Yang, Yu Wang, and Yi Wu. Learning zero-shot cooperation with humans, assuming humans are biased. In The Eleventh International Conference on Learning Representations, 2023.
[5] Andrei Lupu, Brandon Cui, Hengyuan Hu, and Jakob Foerster. Trajectory diversity for zero-shot coordination. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 7204–7213. PMLR, 18–24 Jul 2021.
[6] Micah Carroll, Rohin Shah, Mark K Ho, Tom Griffiths, Sanjit Seshia, Pieter Abbeel, and Anca Dragan. On the utility of learning about humans for human-ai coordination. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
[7] Gessler, Tobias, et al. "OvercookedV2: Rethinking Overcooked for Zero-Shot Coordination." _arXiv preprint arXiv:2503.17821_(2025).
[8] Oguntola, Ini, et al. "Theory of mind as intrinsic motivation for multi-agent reinforcement learning." arXiv preprint arXiv:2307.01158 (2023).
[9] Alain, Guillaume, and Yoshua Bengio. "Understanding intermediate layers using linear classifier probes." _arXiv preprint arXiv:1610.01644_ (2016).
[10] Matiisen, Tambet, et al. "Do deep reinforcement learning agents model intentions?." _arXiv preprint arXiv:1805.06020_ (2018).
[11] Rabinowitz, N., Perbet, F., Song, F., Zhang, C., Eslami, S. A., & Botvinick, M. (2018, July). Machine theory of mind. In _International conference on machine learning_ (pp. 4218-4227). PMLR.
[12] Premack, D., & Woodruff, G. (1978). Does the chimpanzee have a theory of mind?. _Behavioral and brain sciences_, _1_(4), 515-526.
[13] M. Sclar, G. Neubig, and Y. Bisk. “Symmetric Machine Theory of Mind”. In: Proceedings of the 39th International Conference on Machine Learning. Ed. by K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato. Vol. 162. Proceedings of Machine Learning Research. PMLR, 17–23 Jul 2022, pp. 19450–19466.